

 by
by Although partitioned tables seem to be a single physical table when viewed by the user, it is a structure that has as many physical tables as the number of partitions at the database level and when a new record comes to the table, according to our partition structure, the incoming record is placed in the relevant partition. With partitioning, we can think that records are in sub-tables distributed according to a certain rule instead of a single large table. In these very large tables, we can say that it is one of the most effective features of the oracle that will increase our query performance. For example, let’s consider a sales table with 100 million records. When we query this table, the query’s rolling time will be much slower than when we query this data when kept in separate partitions by months.
Let’s talk about the indexing mechanism that will increase our data access performance a little more in partitioned tables.
Indexing can be done in 2 ways in partitioned tables. The 2 index types have different properties from each other. Let’s look at some details.
- Global Indexing
- Local Indexing
Global Indexing
When the table was partitioned, we said that there were as many sub-physical tables as the number of partitions. If we are going to use a global index in the table, an index is created above all partitions and the column of the record is added to the index, regardless of which partition record comes. This global index type is called a Nonpartitioned global index.
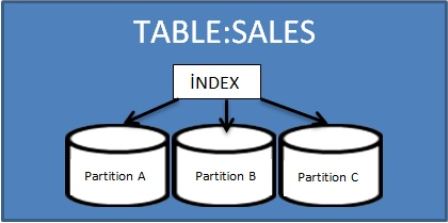
Considering the situation where the table has grown too much, the index will grow greatly and indexed access performance will decrease. In this case, another solution is to partition the global index on the table. In this method, the terminology equivalent is the global partitioned index.
The behaviour of the global nonpartitioned index is the same as the index on a non-partitioned table. The behaviour of the global partitioned index differs in this context. Let’s look at how they were created before looking at this difference.
CREATE TABLE sales
(sales_no NUMBER,
sales_price number,
seller_id number,
sales_date DATE)
PARTITION BY RANGE (sales_date)
(
PARTITION sales_january VALUES LESS THAN (TO_DATE ('01 / 02/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_february VALUES LESS THAN (TO_DATE ('01 / 03/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_march VALUES LESS THAN (TO_DATE ('01 / 04/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_april VALUES LESS THAN (TO_DATE ('01 / 05/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_may VALUES LESS THAN (TO_DATE ('01 / 06/2013 ',' DD / MM / YYYY ')),
PARTITION sales_june VALUES LESS THAN (TO_DATE ('01 / 07/2013 ',' DD / MM / YYYY ')),
PARTITION sales_july VALUES LESS THAN (TO_DATE ('01 / 08/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_agust VALUES LESS THAN (TO_DATE ('01 / 09/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_september VALUES LESS THAN (TO_DATE ('01 / 10/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_october VALUES LESS THAN (TO_DATE ('01 / 11/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_november VALUES LESS THAN (TO_DATE ('01 / 12/2013 ′, 'DD / MM / YYYY')),
PARTITION sales_december VALUES LESS THAN (TO_DATE ('01 / 01/2014 ′, 'DD / MM / YYYY'))
);
Global NonPartitioned Index

Create index npi_saller_id on sales(saller_id);
Global Partitioned Index

CREATE INDEX npi_saller_id ON sales(saller_id) GLOBAL PARTITION BY RANGE(saller_id) ( PARTITION indp1 VALUES LESS THAN (10), PARTITION indp2 VALUES LESS THAN (20), PARTITION indp3 VALUES LESS THAN (30), PARTITION indp4 VALUES LESS THAN (40), PARTITION indp5 VALUES LESS THAN (MAXVALUE));
The point that should be considered in the global partitioned index is the growth of the partition limited to MAXVALUE of the column we index. In this case, it will be necessary to split the partition limited to MAXVALUE in case the records containing the value to be reduced to this part increase. Otherwise, the number of entries in this partition of the index will grow and the performance of the queries that will run on this index will decrease.
Another thing to note here is that when we delete one of the index partitions, we need to rebuild the index so that we can use the remaining indexes.
Let’s drop an index partition here and look at the status of other index partitions.
ALTER INDEX npi_saller_id DROP PARTITION indp3; SELECT partition_name, status FROM user_ind_partitions WHERE index_name = 'NPI_SALLER_ID'

When we drop the partition number 3, it seems that the next index partition is unusable. To prevent this situation, we can run the following SQL statement.
ALTER INDEX npi_saller_id REBUILD PARTITION indp4; SELECT partition_name, status FROM user_ind_partitions WHERE index_name = ‘NPI_SALLER_ID’ PARTITION_NAME STATUS —————————— ——– INDP1 USABLE INDP2 USABLE INDP4 USABLE INDP5 USABLE
Local Partitioned Index
Local partitioned Index foresees to create an index for each partition of our partitioned table. It is very easy to use and maintain compared to others. Oracle automatically performs index synchronization for each partition and keeps indexes up to date. It evaluates the partition to which it is linked with each index in pairs and makes it independent from other binaries. In this way, the problem to be experienced in any binary does not cause any problems in other pairs and the indexes continue to work in a healthy way. This situation is not only related to the problems but in cases where any partition on the table is moved to another physical disk, only the table index binary is affected. In this way, the table can be kept constantly available.
The important thing to note in Local Partitioned Indexes is that we cannot add a new partition to the local index with an external command. To do this, adding a new partition to the indexed table will mean adding a new partition. Likewise, it is not possible to drop a partition from the index externally. To do this, it is sufficient to drop the relevant partition of the table indicated by the index.
CREATE INDEX npi_saller_id ON sales (saller_id) LOCAL;
When the properties of Local and Global Indexes are examined, it can be seen that it is more appropriate to use global indexes for OLTP systems and local indexes for OLAP systems. However, this decision is not a generalization, it is our need that is decisive. It is possible to say this judgment in terms of its basic characteristics because OLAP systems are systems where querying is done and data in large size compared to OLTP systems are therefore very important for the continuous availability of the tables, the speed of access to the data after partition pruning and the uninterrupted reporting. critical (DSS). Besides, it is easier to maintain Local Indexes. Any maintenance work that will affect the Global Index may require rebuilding of the entire global index.



