by
by As a leader in DLP solutions, McAfee provides data protection structures in many institutions with integrated solutions. With McAfee DLP (Data Loss/Leak Prevention), it is necessary to define sensitive data that needs to be protected in order to provide data protection. This definition is provided by Classification, one of the most important topics of DLP. A DLP is unthinkable without Classification. Because the classification part is where personal data, sensitive data for us, are defined. Without identifying personal data, it is not possible to protect and examine these data.
Classification Options
Classification is divided into 2 options in McAfee ePO. One of them is automatic classification and the other is manual classification.
-
Manual Classification
Manual classification is actually the part where users are given the opportunity to classify. In other words, the user defines the personal data by choosing any of the classifications defined on the McAfee ePO. For example, when the user creates a Word document, you can create a warning that this file must be classified, and the user will classify the document by choosing one or more of the classifications specified in the McAfee ePO. In general, it is not recommended to use only manual classification. It is safer to use with automatic classification. Manual classification may be preferred to raise awareness of the user.
-
Automatic Classification
The use of automatic classification in DLP is an ancient classification. This classification is a system that automatically performs the classification process by finding the data to be classified in certain places in the system (Cloud, Files, applications, etc.), which is created without being left to the user’s control. For example, it can be said that only personal data in a certain location should be classified.
McAfee ePO Classification with 2 Different Ways
McAfee ePO can classify data in 2 different ways as classification. One of them is Content-Based classification and the other is Content Fingerprint classification.
1. Content-Based Classification
Content classification can be done by typing certain regex records, as well as the TCKN, credit card patterns that come ready in Content-Based classification. In Content-Based classification, the data is looked at. For example, if encrypted mail is sent, it cannot prevent it.
Creating Classification on ePO
You can follow the “Menu -> Classification -> Action -> NewClassification” steps to create a classification on ePO.

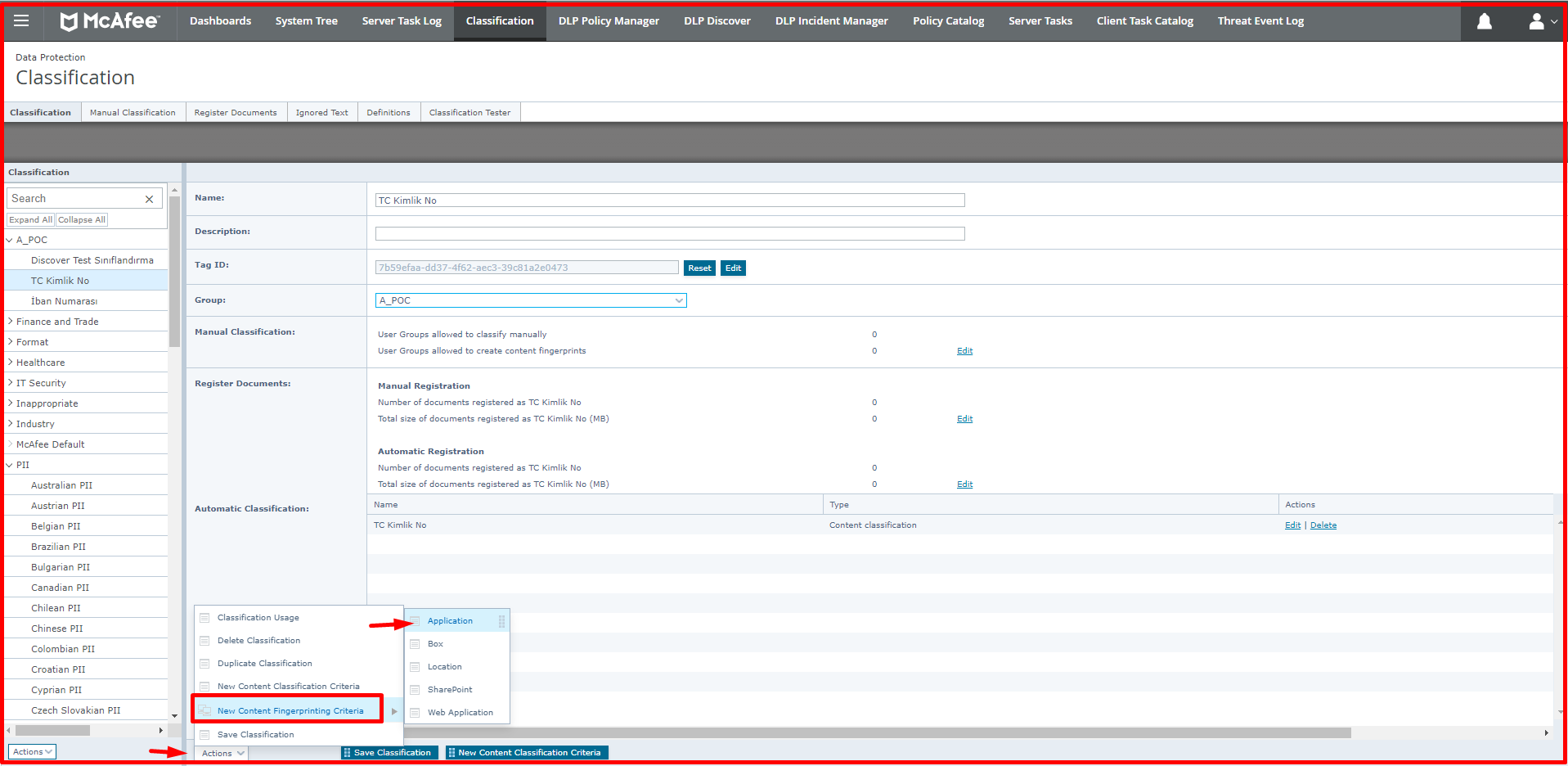
Desired criteria can be created under this classification. In the example below, we have defined sensitive data under the “A_POC” classification for “TR Identity Number” and “IBAN Number“. You can also create a classification group in the Action section here. For example, the Personal data classification is in the “A_POC” Classification group.
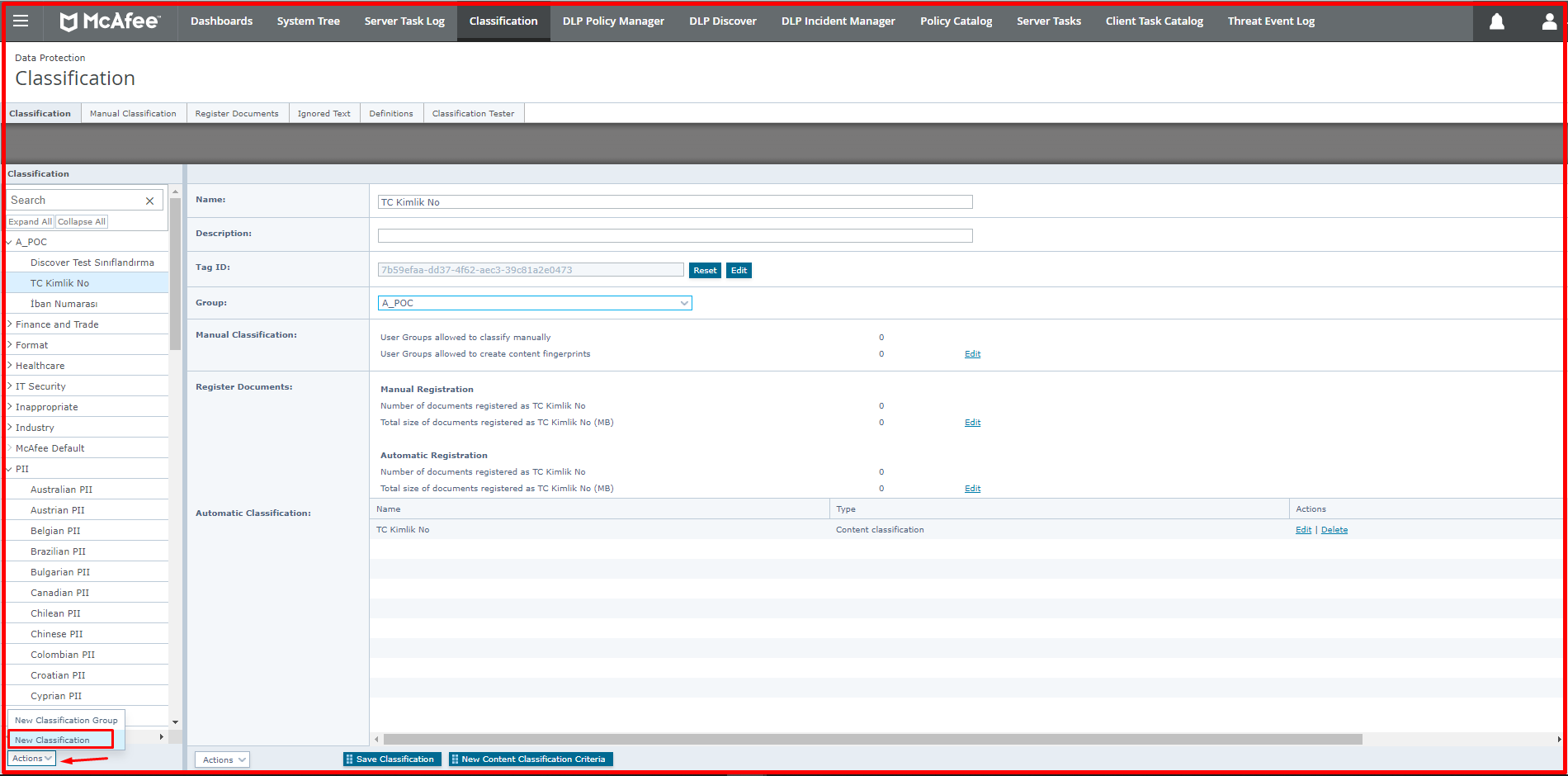
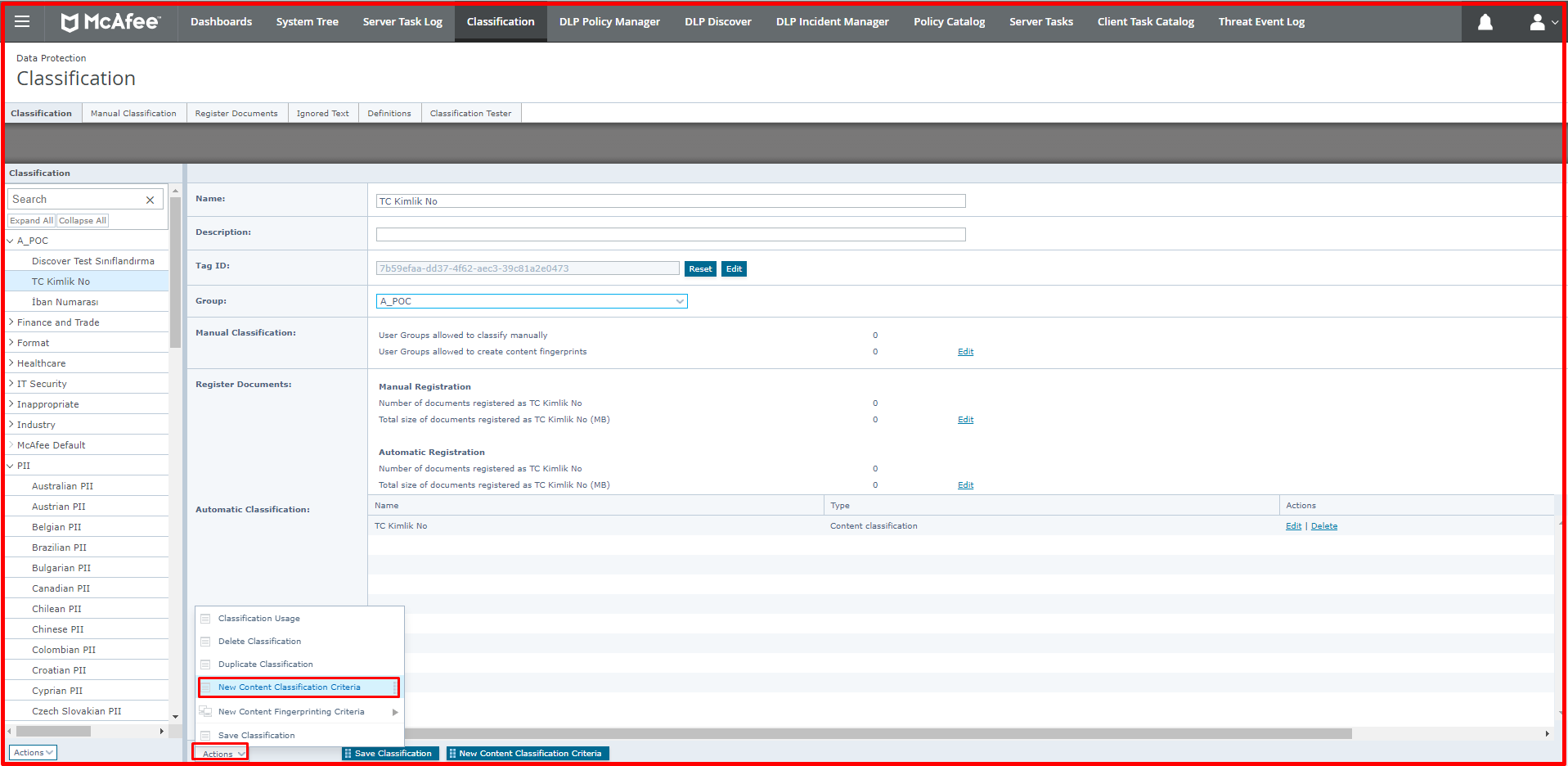
After giving a name to the created Classification, for example, when you want to make a classification related to Content-Based classification, you can create new data for the classification from the “Actions -> New Content Classification Criteria” section by selecting the created classification in the left. A screen like the one below will appear. We will briefly talk about these tabs below.
Here, definitions are divided into two data content and file content. We will be talking about the most used definitions.

Advanced Pattern: There are many ready-made templates such as TCKN and IBAN. It can be created in patterns other than ready-made templates. A Regex record is used to create these patterns. For example, if you want to define the phone number as sensitive data, you can create the Regular Expression of the phone number and define it from this section. Regular Expression is also known as a regular expression. And these expressions can be formed by certain methods.
Dictionary: Sensitive words to be classified can be defined in this section. Many word definitions can be made. In addition, if the specified word occurs 10 times, for example, it can be said that the file should be classified. If a word is specified with “Case Sensitive”, only the specified word can be classified as sensitive data as case sensitive.
Keyword: While many word definitions can be made in Dictionary when classification is required for a single word, the definition can also be made from the keyword tab. In this way, for example, if you define CV as a keyword, files containing the word CV will be counted as valuable data and data protection will be ensured according to the rules created.
Exact Data Matching: It is a feature that can be used in databases with DLP Discover. For example, you can use this feature when you want to provide protection by preventing the simultaneous output of many data such as name, date of birth, not just the data containing the TCKN.
File Extension: Classifications can be provided according to the file extensions determined by File Extension. With File Information, data classification can be made according to options such as files with a specific file name or a certain size, files created by a specific person.
File Encryption: With this option, definitions such as if a file is encrypted by FRP or Azure’s encryption system, this file should be classified and then protected. Many encryption methods come by default.
Third-Party Tags: Data labelled with Titus or Boldon James can be classified as labelling.
2. Content Fingerprint Classification
Application-based, location-based and web application-based classifications can be made with Fingerprint classification. When we specify a file based on location, DLP can classify the data in the file when the file is opened, copied, when an operation is performed on it, and when the file is accessed. For example, when you use this classification as a public folder, all files in the public folder will be classified. In the example given below, the files with the extension “DOC, DOCX, DOT, RTF” will be classified among the files in this folder. The location to be classified here is defined in the Network Shares section. There are also definitions that come ready-made in this section.
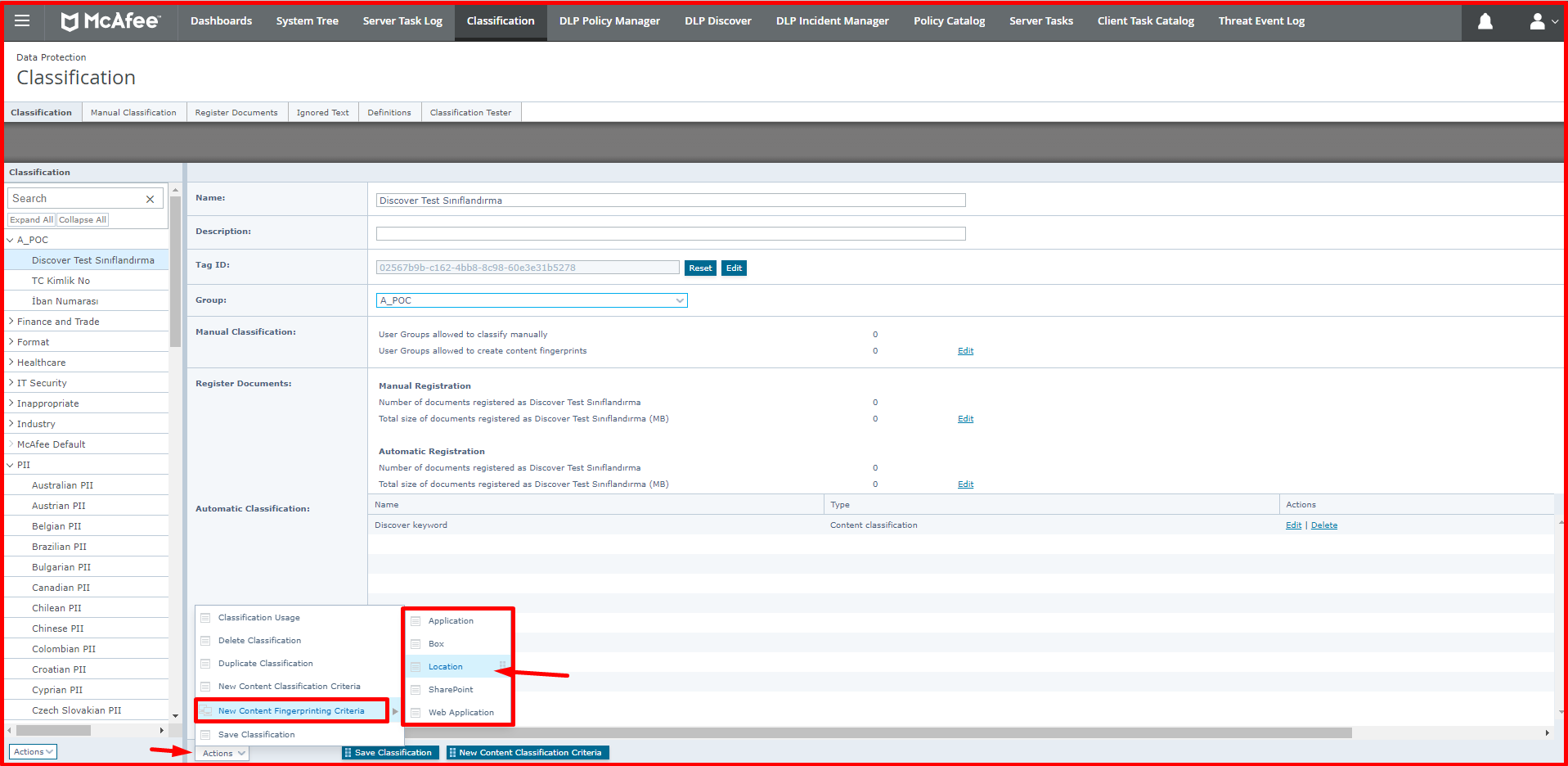
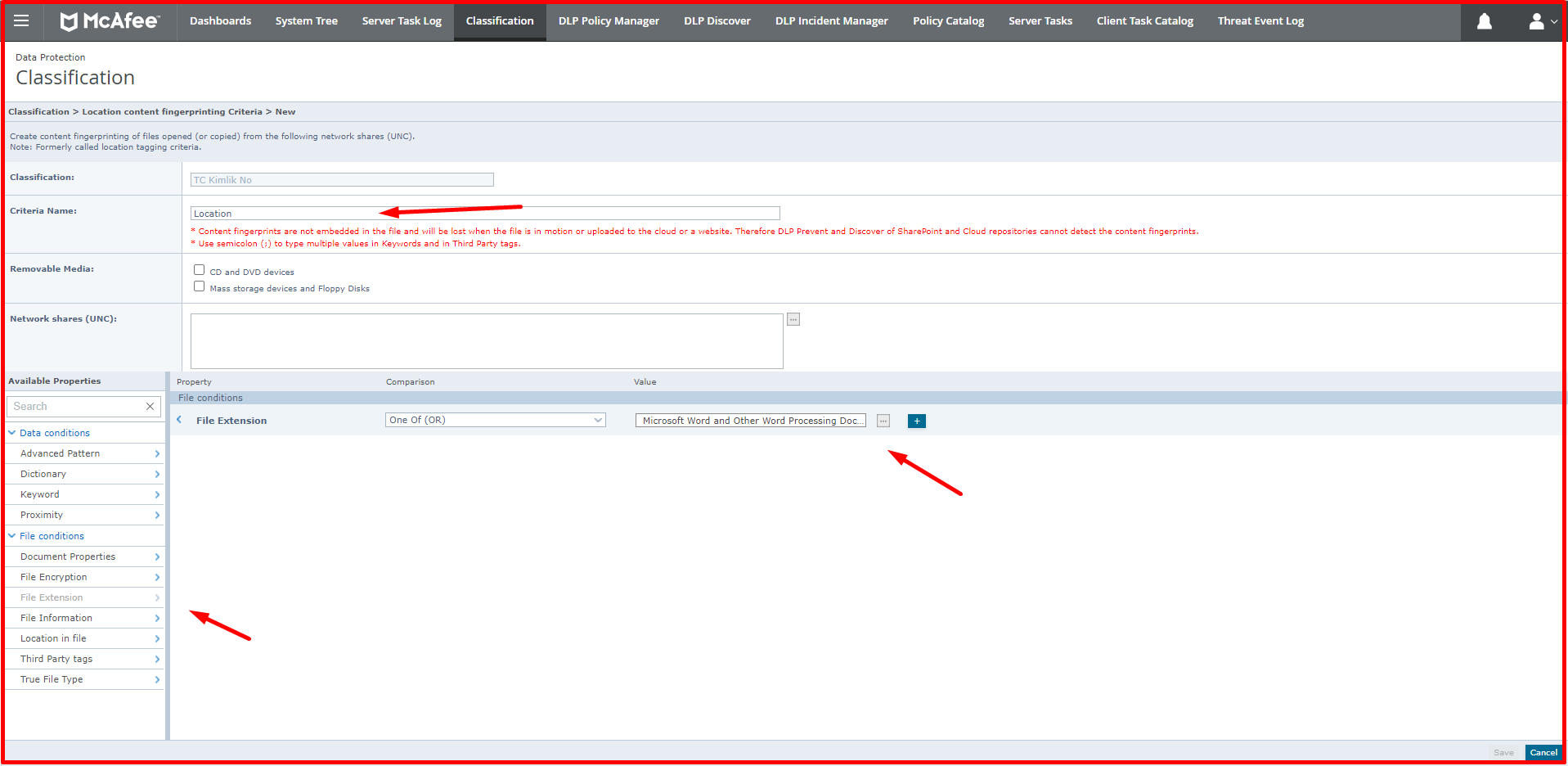
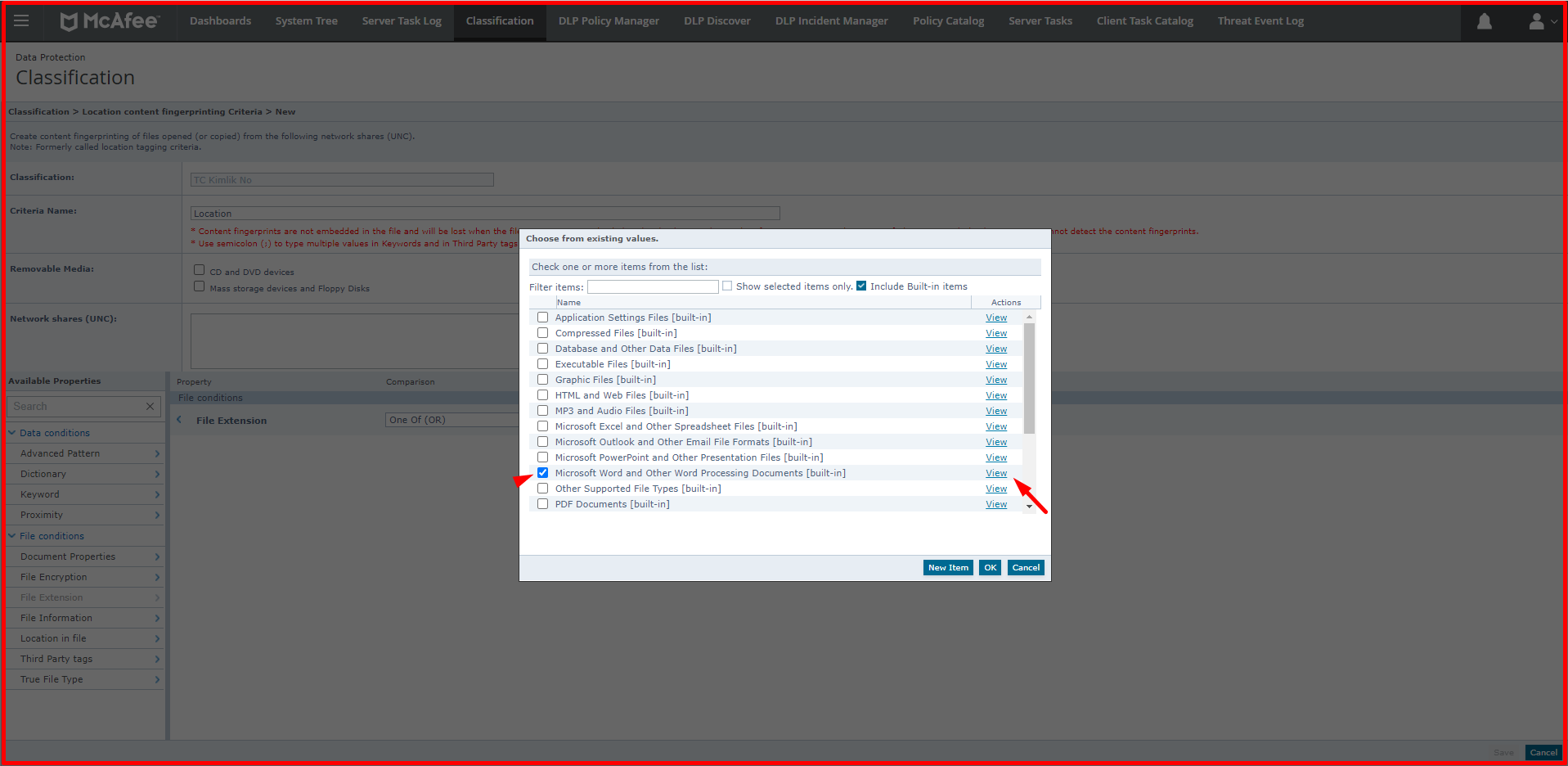
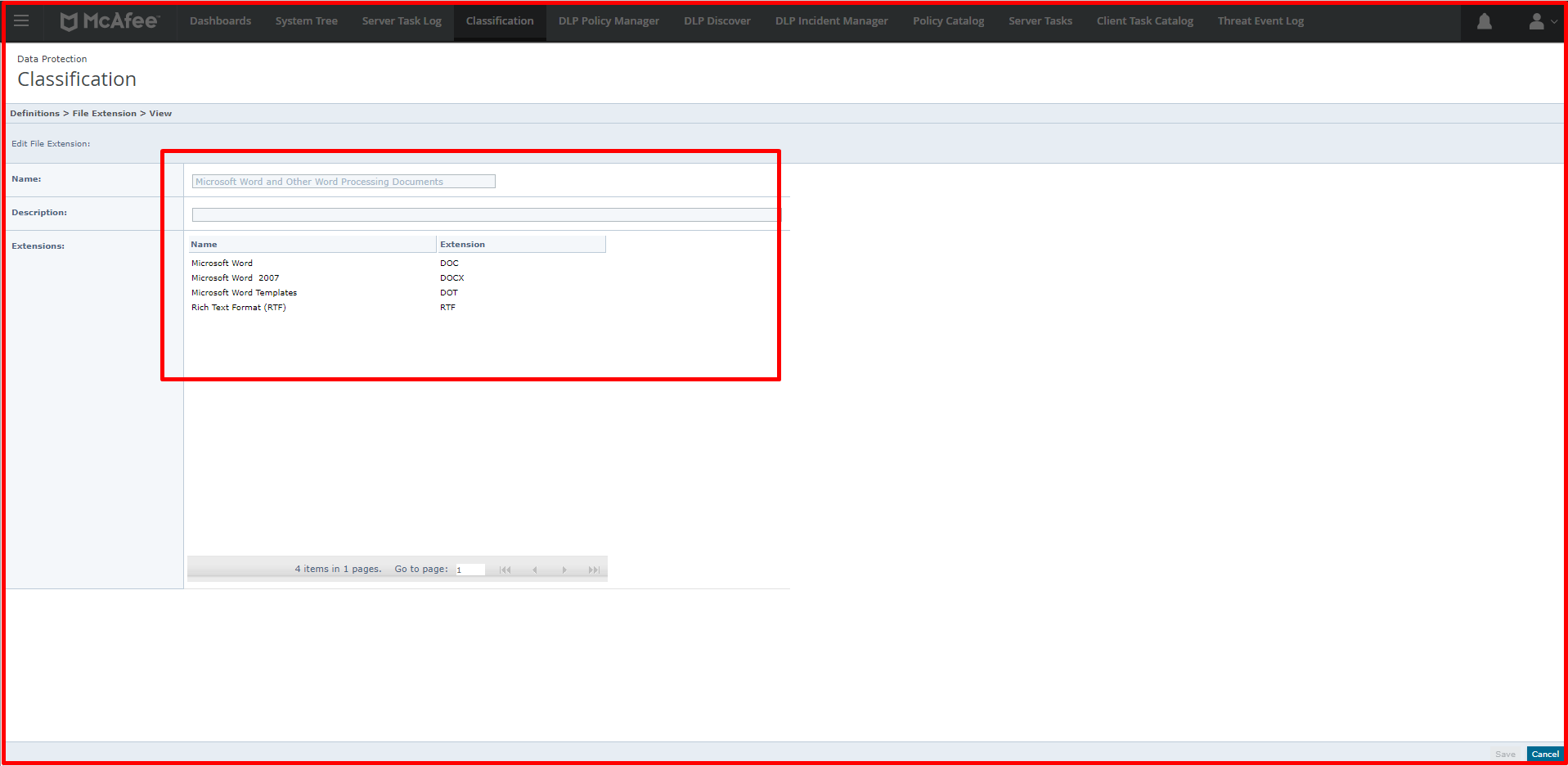
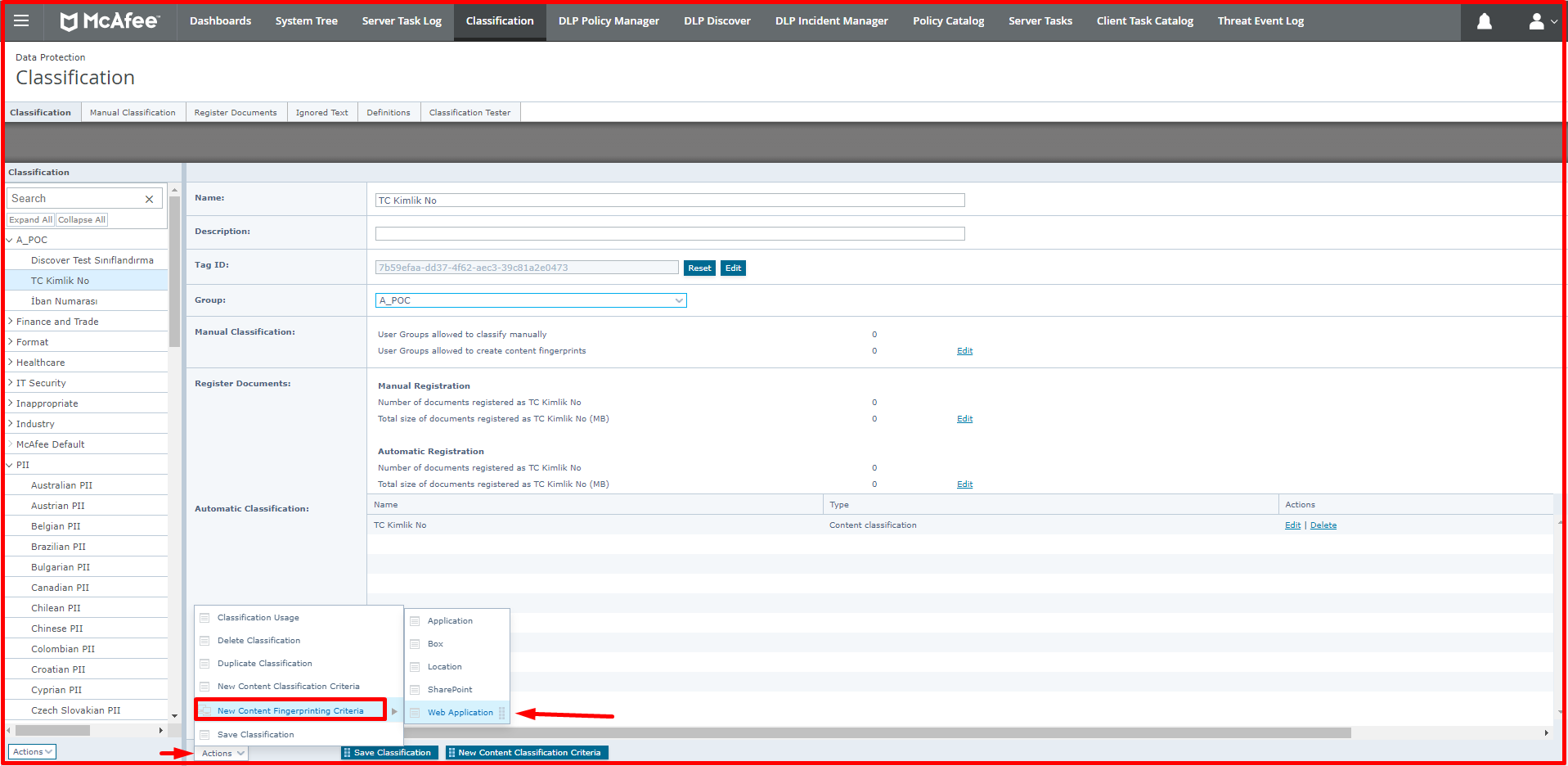
With the application-based classification, a new application can be defined or definitions can be made over the applications that come ready. For a new application, a template can be created according to certain options. You can define a new application via “Classification -> Actions -> New Content Fingerprint Criteria -> Application”. You can use certain options, such as the original extension, to the file extension of the application, and you can classify the data that comes out of this application. Many templates are coming. When you have an accounting program or a finance application that provides data output, you can make definitions from this section.

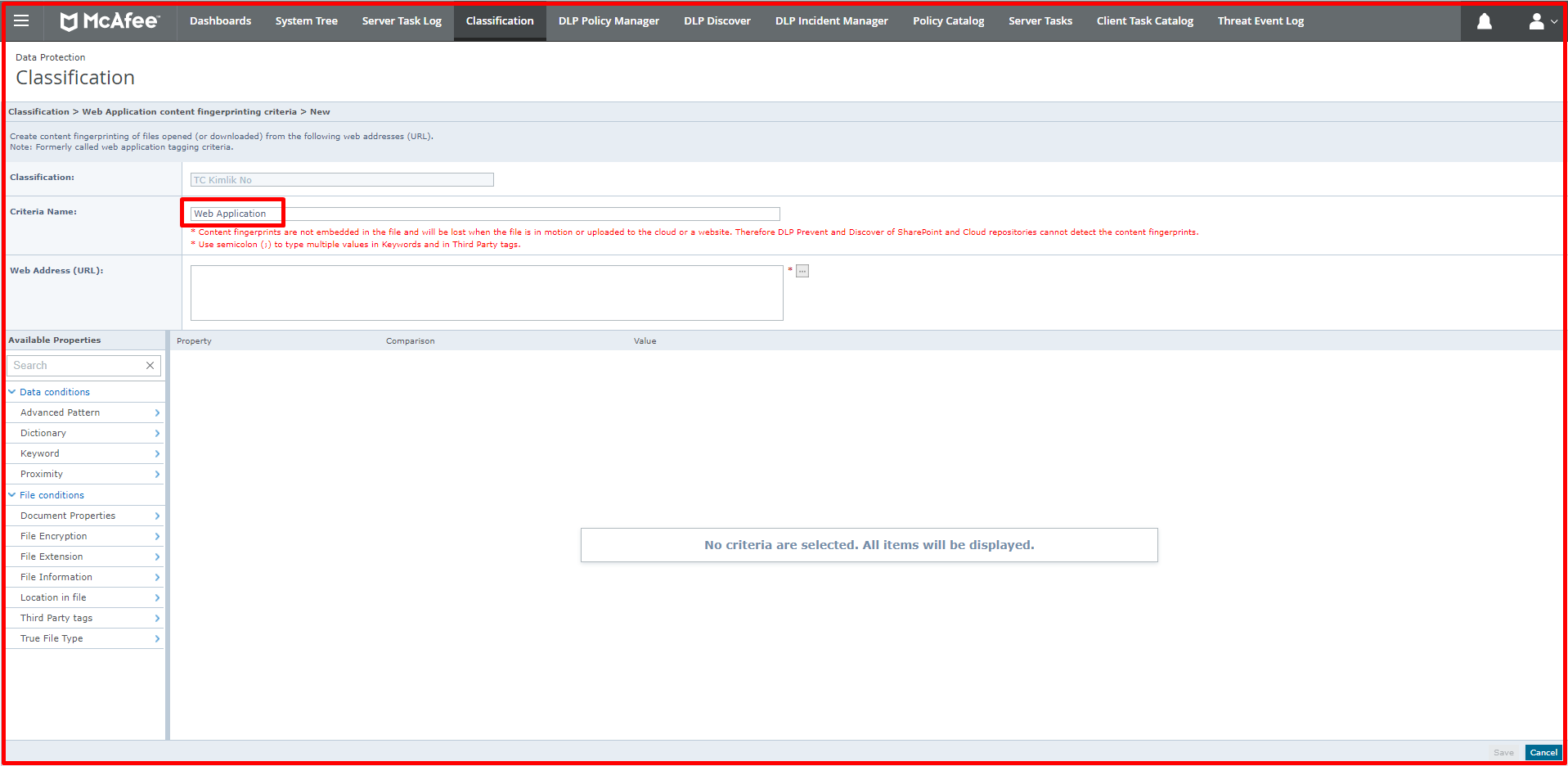
The classification of data and files obtained from the URLs of web applications, which are also defined by Web Applications, is provided. For example, by specifying the URLs of a bank or insurance company that can be accessed via the web, the data obtained from these can be classified.
We will briefly talk about some tabs in the Classification section.
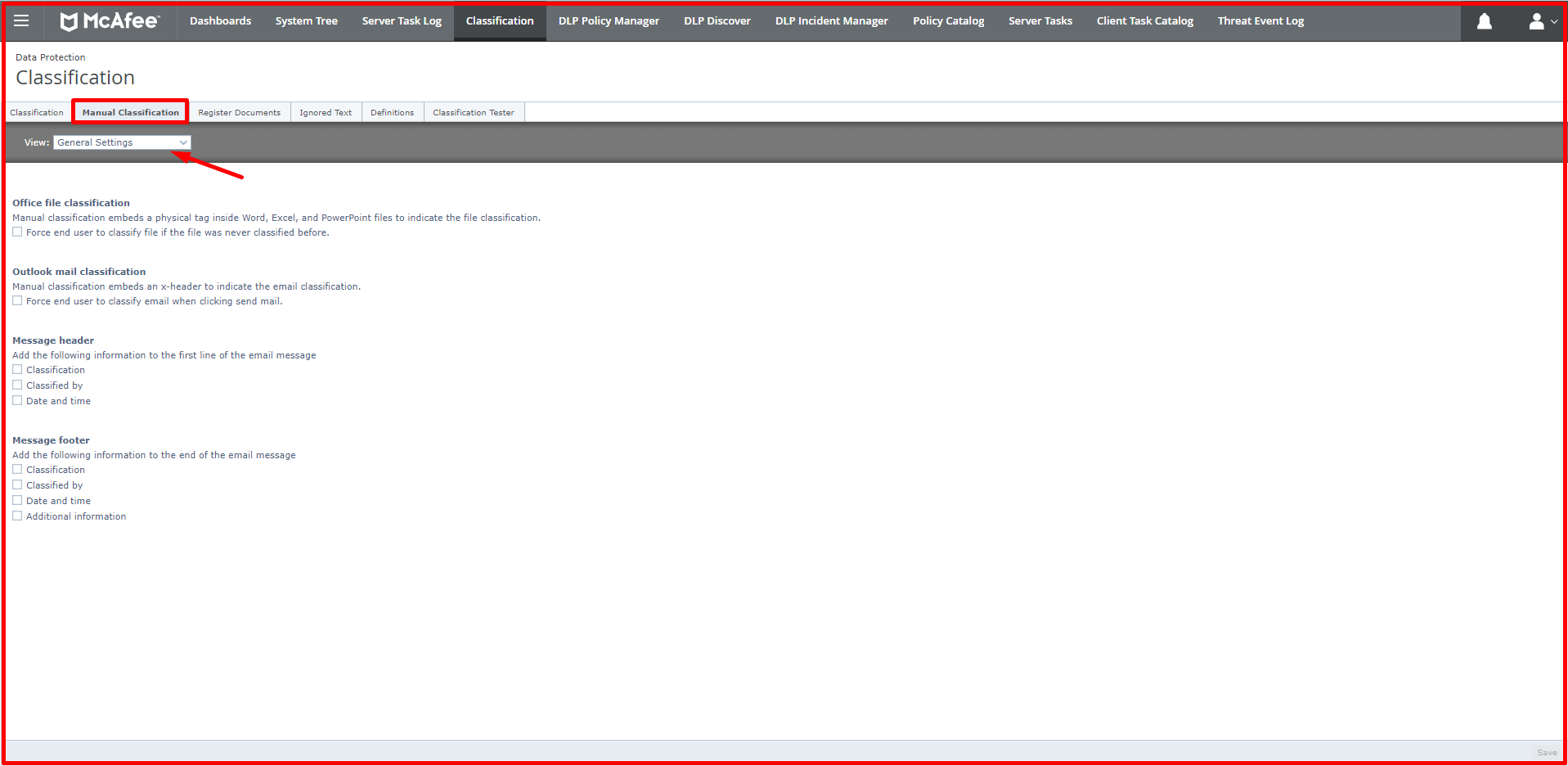
Manual Classification: In Manual Classification, there are settings such as which users can manually classify, optional or mandatory classification options.
Register Documents: This page is used to review registered documents, upload documents and create signature packages.

Definitions: In the Definitions tab, there are templates that come readily when classifying. In addition, new definitions can be made here.
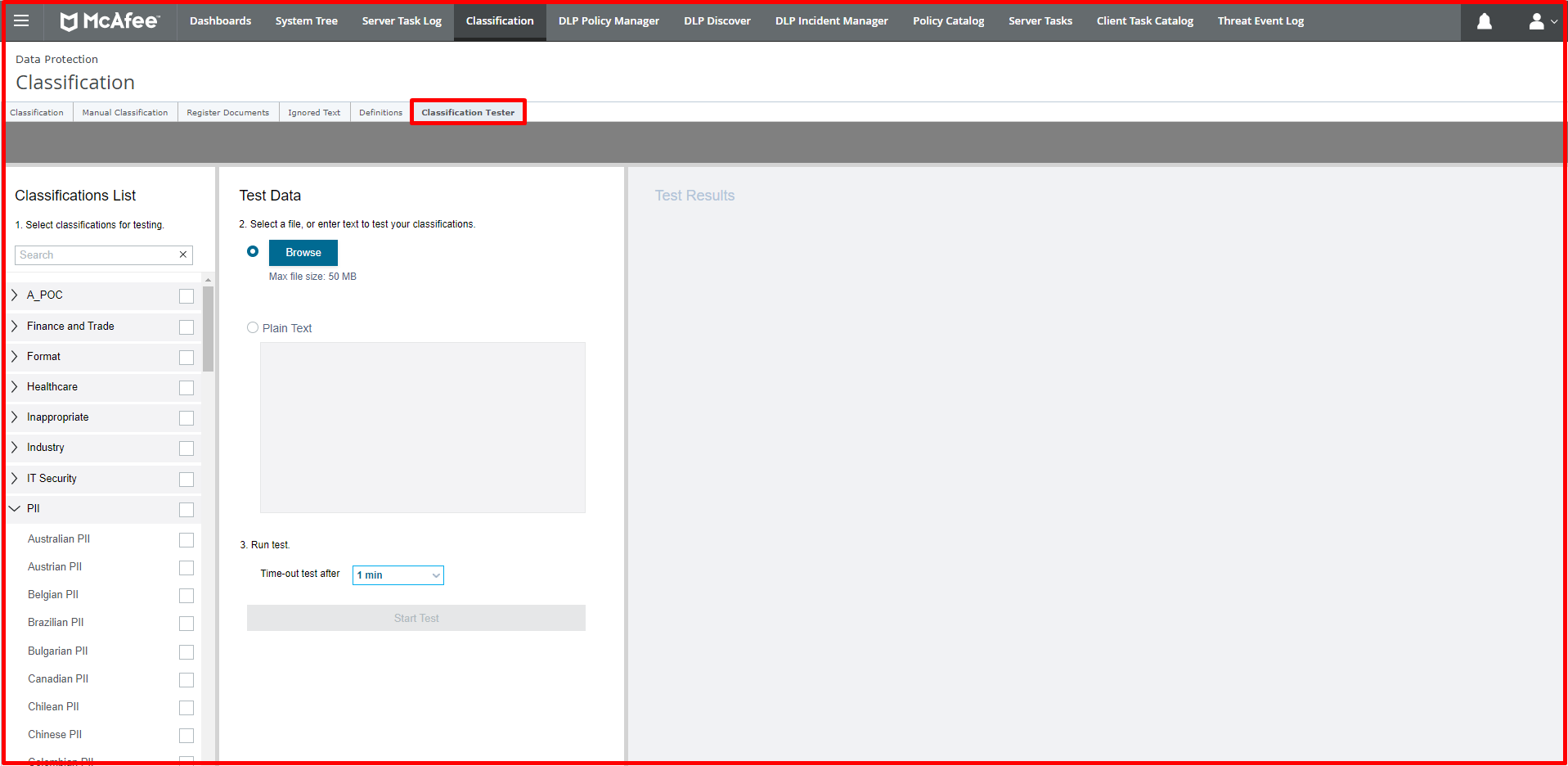
Classification Tester: Classifications created with the Classification Tester section can be tested. Only classifications created with content criteria can be tested here.